What Happened
In the most recent Kubernetes SIG-Network meeting (2020-04-02), a meta issue was raised. People had noted a decrease in new network-related issues. The reason, it was discovered, wasn’t that new issues weren’t being filed. It was that new issues weren’t being labelled in the way they were normally labelled.
The Kubernetes Github repo has a fixed set of issue labels,
which are managed by a bot
(through automatic triggers, and comment commands).
In particular,
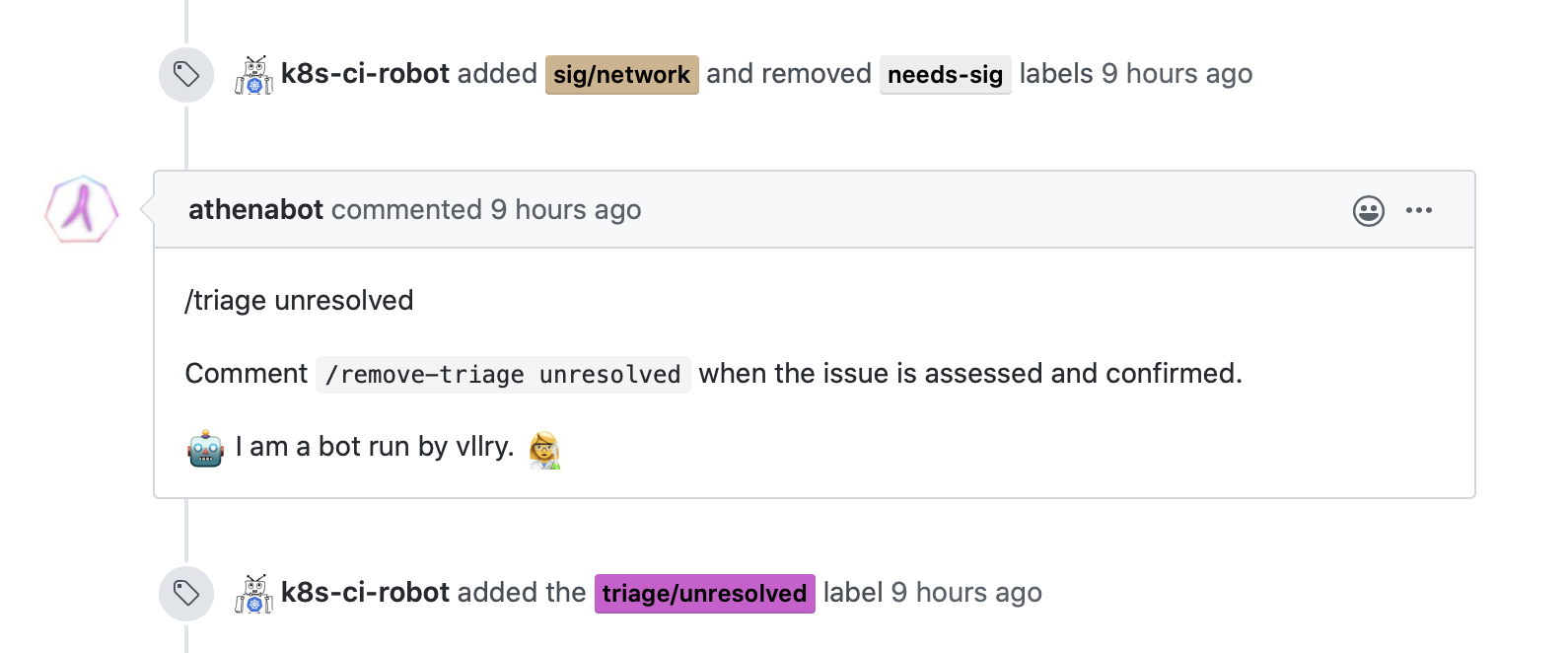
all issues are labelled with either needs-sig,
or one or more sig-___ labels.
SIG-Network issues are labelled with sig-network.
Starting in early 2019,
SIG-Network made a point of gradually burning down the issue backlog.
We starting applying an “old” issue label,
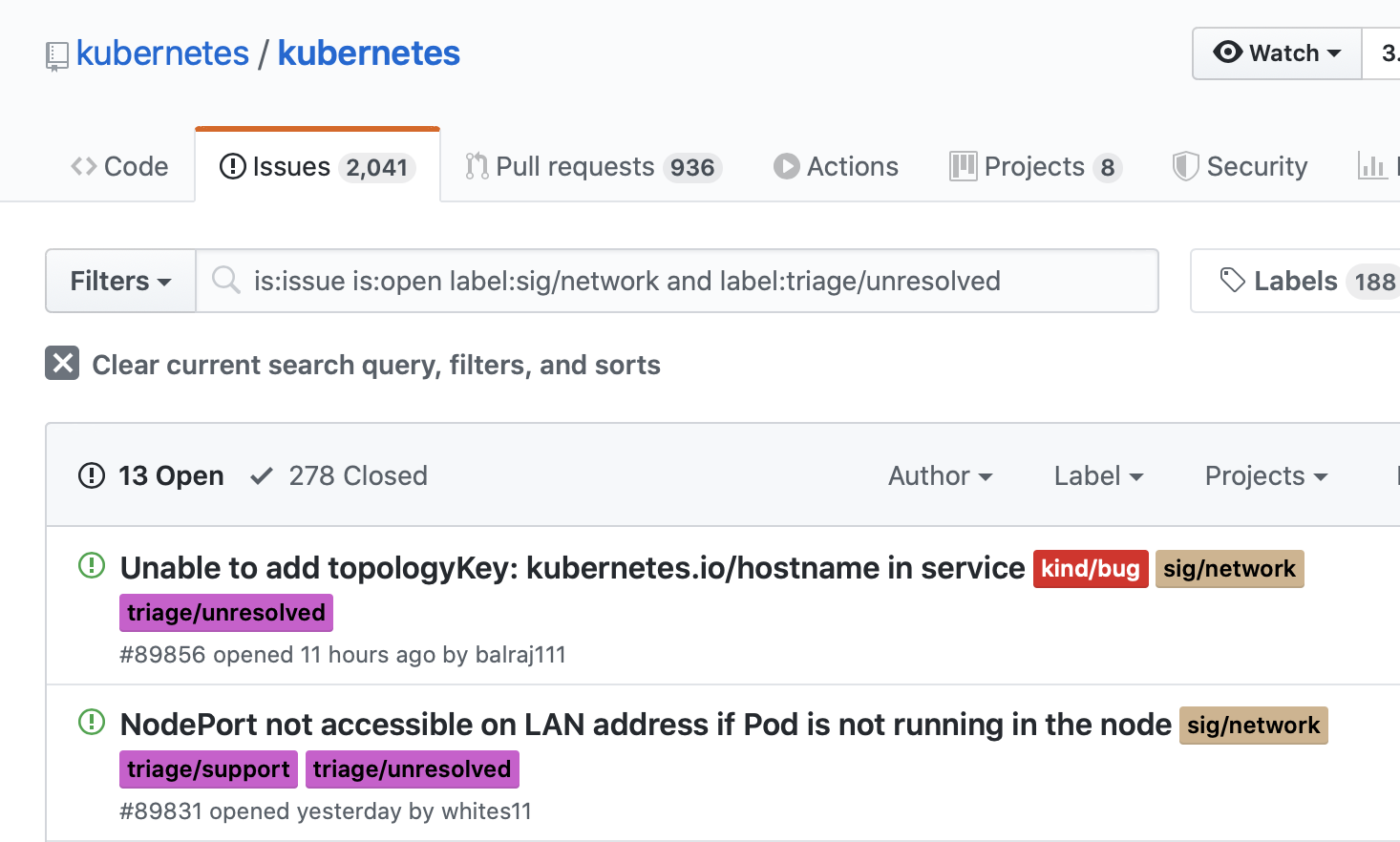
triage/unresolved,
to all open SIG-Network issues that had not yet been inspected and verified/prioritized.
Once an open issue was confirmed to be legitimate,
a member would comment /remove-triage unresolved to remove the label.
This allowed us to easily filter between the inbound and triaged issues.
This process was a bit tedious,
and relied on individuals regularly stepping up.
To alleviate this,
I created a simple Github bot,
called athenabot.
Athenabot has several functions,
however the primary function of athenabot is to label new sig-network issues
with triage/unresolved.
This functionality had broken, for a total of 24 days.
Athenabot runs as a Kubernetes CronJob, on a tiny cluster that I use for medium to long term experimentation. Kubernetes CronJobs are configured with a traditional cron stanza, and launch a pod when it is time to run.
Capacity in Kubernetes is measured by requests of CPU and memory. All pods can specify requests (EG 1 CPU, 1 GB memory). When pod scheduling occurs, the default scheduler behavior is to only consider nodes where the sum of requests would not exceed the total machine resources. Athenabot’s pods were set to request 50m CPU (5% of a CPU), and 64Mi memory when launched.
The cluster was both over capacity, and using an ephemeral VM. Periodically, the VM would shut down, and there would be no node available to run workloads. When a new node booted, all existing pods would need to be re-scheduled on to the node. As not all pods could fit on the node, due to CPU requests exceeding capacity, some would remain unscheduled. There are multiple possible combinations to fill a node. As a CronJob, athenabot’s pod would not always exist (it only exists for roughly 30 seconds, every hour), which meant that it often would not even be considered in initial node scheduling. The athenabot pod may not be scheduled in a given combination, or the scheduling may not leave a 50m CPU “hole” for a future pod to claim. This would cause periodic scheduling failures. There is not enough data to indicate exactly how often this occurred.
CronJobs have a known design flaw that will cause repeated scheduling failures to become “permanent” in specific conditions. CronJob schedule parsing is inefficient at large scale, when checking over long timespans and many iterations. When deciding if a pod should be launched, the CronJob controller iterates over all cron schedules times, from the most recent run time to the present. There is a cap on checking at most 100 consecutive schedule times.
The “100 missed starts” failure was recognizable by mentally pattern-matching against CronJob and child Job statuses, and seeing 24 days since a run had occurred. It was verifiable by checking events and seeing the error.
$ kubectl get cronjobs -A
NAMESPACE NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
athenabot athenabot-k8sissues 12 * * * * False 0 24d 166d
The CronJob initially failed to schedule because a pending pod already existed (and the CronJob had a concurrency policy that forbid concurrency).
In order to hit the terminal failure, the CronJob must have not run scheduled for at least 100 schedule times, and one of the following must be true:
There is no starting deadline (
startingDeadlineSeconds = nil)The starting deadline exceeds the span of the last 100 missed schedules (e.g. schedule is minutely, starting deadline is 120 minutes)
Athenabot hit the former case.
At some point,
some combination of “unlucky scheduling” and ephemeral VM unavailability led to
(at least) 100 consecutive schedules where an athenabot pod could not run
(which may have been as low as “just over 99 hours”, depending on exact timing).
At that point,
the CronJob could never run again without human intervention.
There are multiple possible resolutions
(setting startingDeadlineSeconds, setting a fake recent lastScheduleTime, or recreating the CronJob).
I opted to set a startingDeadlineSeconds.
Setting this time allowed the CronJob to continue running.
Issue labelling has resumed,
and I am making sure that the backlog is labelled.
Takeaways
There were multiple, unideal decisions made:
- Running what is functionally a “production” workload in a fragile test environment.
- A lack of any monitoring.
- Non-robust configuration of the CronJob.
Perhaps, using a Kubernetes CronJob altogether was the wrong approach. Kubernetes CronJobs are complex (adding 2 layers of abstraction, themselves and Kubernetes Jobs), plus pod scheduling and management concerns. A traditional cron would still be vulnerable to similar neglect, but as a less mechanically complex system, has far fewer failure modes.
Additionally, the athenabot CronJob has unnecessarily large requests. In practice, less memory, and substantially less CPU than the requested values is needed. Setting these lower would not have prevented this particular incident, but is prudent nonetheless. Removing the requests would have prevented this incident. Requests are only for scheduling bookkeeping - they do not represent a guarantee, or enforcement. Setting no requests would allow the CronJob to schedule on to a node regardless of capacity, and the athenabot process is too small to cause undue strain on the node’s resources. However, making a decision like this at larger scale (with larger and/or more workloads) can become impactful.
There is an open proposal gaining traction to build the triage label automation into the official Kubernetes Github automation. Regardless of having the athenabot code be open-source, there is risk in productivity tooling being maintained and hosted by a single individual. Additionally, the triage workflow has been useful within the SIG, and will likely be helpful for others.
Additional Commentary
I was quite exasperated to hit this issue in a personal setup, as this is something we patched at Lyft, and I am working on porting into upstream Kubernetes (a draft upstream PR is here). As that’s some work-work content, I’ll save commentary on that for another venue.