I’ve been using Kubernetes for a few years now, between 2 pretty different companies. Supporting multicluster applications was a problem that rapidly grabbed my attention. Kubernetes clusters are nontrivial failure zones, and due to the internal communication model, are meant to be deployed in a single location. This poses a challenge if you support a system with high uptime/reliability concerns, and/or need to support multiple regions in your business.
I’ve tried a whack of tools, including the Kubernetes alpha “Federation” back in 2017. They mostly worked, but had a lot of pain points, and tended to make many assumptions that I would have to orient other infra (or even applications) around.
I had a really enlightening conversation at the most recent Kubernetes Contributor Summit (San Diego 2019), about this general problem space. Timothy St. Clair raised a point about kubeadm, and why it gained traction. kubeadm is a horizontal solution to solving cluster provisioning. It solves a specific area of provisioning problems well, and doesn’t attempt to be an “all in one” solution. Users and vendors are left to solve things like machine provisioning, and higher-level cluster management on their own. In contrast, many tools like Federation, or “GitOps” solutions take a very opinionated approach, which I found made them hard to adopt. They have specific opinions, which might not line up with the desired behavior.
In this post, I’m going to propose a model that’s been sitting in my head for a year and a half, which I’m convinced would serve as a general-purpose building block for building multicluster systems.
The Problem
I’m presupposing that you have (or ought to have) multiple clusters. Whether a typical Kubernetes user should need many clusters is a different can of worms, but the reality is that a production app on a single cluster is a gamble, all other reasons aside.
Let’s start with a simple example.
You have $n clusters,
and want to run the same software on all of them.
Maybe this is a redundant pair,
multiple points-of-presence (POPs),
whatever.
Your simplest approach is to take your deploy system -
let’s be real, Jenkins running kubectl apply is the industry standard -
and point it at all applicable clusters (“this gets deployed to prod-1, prod-2, prod-3”).
This isn’t too complicated, and it mostly works.
However, picking specifics will easily become cumbersome, and tightly ties the deployments and tooling to infrastructure. New clusters are under-utilized, due to many existing workloads not targeting them for deployment. Deleted clusters must have their workloads moved elsewhere, and must be detangled from every system/tool that directly references them.
We also face problems such as “how do we garbage collect resources when we stop deploying to a cluster?” There’s solutions to these pain points, but initially simple hacks can get messy at larger scales and higher change velocity.
Now let’s look at a harder case: let’s say we have multiple applications. Maybe some of them shouldn’t or can’t be deployed everywhere, such as BI data centralized in one place, mixed security/reliability classes, small apps not worth a full global deployment, and so on. Those are some really messy and complex Jenkins pipelines.
The General Approach
As designers/administrators of a system, we have high-level acceptance criteria for workload placement. Back in 2018, I had a brainstorm with other QCon SF attendees, and we identified 3 fundamental criteria for placement:
- Specific levels of redundancy.
- Specific kinds of geographic/topological placement or spread.
- Specific resource availability.
In a large system, there are many valid placement solutions to solve a given set of constraints.
What if, as an administrator, I could say
“this app should run in every region”?
Or “this app should run in 2 regions”?
Or “this should run in this bundle of regions/AZs?”
Many users,
rather than targeting explicit hardcoded clusters in their deploy pipelines,
are using some form of label selectors for their cluster targeting.
For example, region=us-central1, tier=critical, or app=storefront.
If these labels are exposed in a central location,
other tooling can also reference them,
and translate a label to a set of non-fixed clusters.
The Components
The Workload API

This entire system must be backed by an intent-based API, rather like Kubernetes itself. We’ll discuss this in terms of individual APIs, for the sake of separation of concerns, starting with the Workload API.
We obviously need a way to represent workloads in this system. At a high level, you specify your workload itself, cluster selectors, and cluster replication parameters.
workloadId Uuid
objects Objects
selector Selector
clusterReplicas Int
We will return later in more detail to what the Objects and Selector types could look like. For now, assume that an Objects is a list of Kubernetes objects (of arbitrary kinds), and a Selector is a map of key-value string pairs (where all must match a cluster). ClusterReplicas is the number of clusters to target.
type Workload struct {
workloadId Uuid
Objects []kubernetes.Object
Selector map[string]string
ClusterReplicas Int
}
Note that this prescribes nothing about what a “workload” is. It’s an arbitrary bundle of whatever Kubernetes objects. Maybe it’s a Service/Deployment/ConfigMap bundle. Maybe it’s the entire set of backends necessary to serve a given API. It doesn’t matter, as long as the specs don’t self-mutate (and therefore can be re-applied idempotently from the original definition). If a user wants more opinionation about what a MultiCluster service or similar is, they can build it themselves on top of the Workload API and underlying clusters.
The Cluster Registry
As well as knowing what Workloads to run, we need a cluster registry, which stores the following for each cluster:
- Cluster ID.
- Cluster address.
- Cluster labels.
- Cluster secret.
- Cluster health and status (could be as simple as a bool for “reachable/responsive”).
With the registry, we are aware of all cluster-level scheduling options.
If a push-based model is being used, the Cluster Registry must a store service account token for each cluster. In a pull-based model, the cluster could store something like a public key for an agent secret. We’ll discuss more on push vs pull later.
Cluster health and status is a complex topic, and I am only going to handwave it in this post. Ideally, the API supports custom data, either directly (e.g. key-value fields), or with a custom API type (e.g. ClusterStatus, which is custom, references the ID of the standard Cluster type). Any health/status information would need to be understood by the scheduler. Speaking of which…
The Scheduler
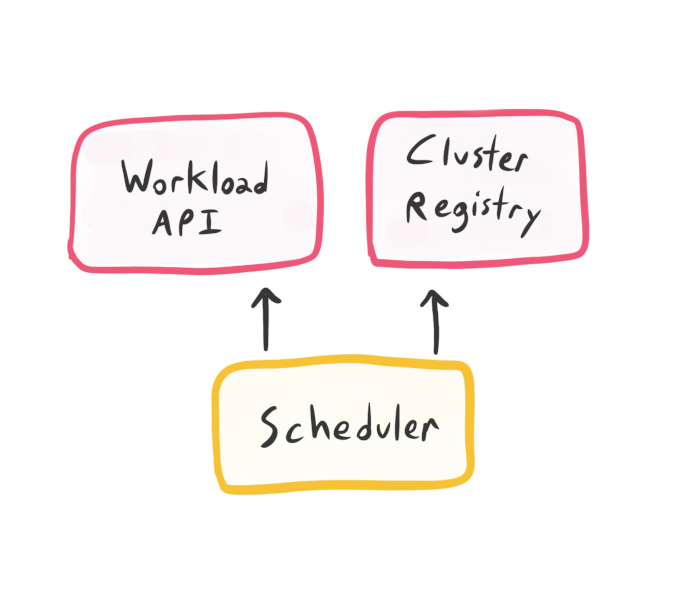
Scheduling should be done by a discrete component, which updates the Workload API (or a separate Placement API) with scheduling decisions. This allows users to write a custom scheduler (or swap out pre-made schedulers), without monkeying with the Workload API’s internals.
We need to expand the Workload API, as it must convey the cluster placement for each workload. Let’s say each Workload object has a unique ID (i.e. autogenerated UUID). Given that, we can record the scheduler’s mapping of Workload to cluster in some form, e.g.:
// workload -> clusters
type WorkloadClustersMapping struct {
workload WorkloadId
clusters []ClusterId
}
// clusters -> workloads
type ClusterWorkloadsMapping struct {
cluster ClusterId
workloads []WorkloadId
}
Scheduling is done by finding a set of clusters that satisfies the Workload’s match selectors. Let’s assume that the Selector sub-API is the simple one outlined earlier, i.e. the Selector is a set of key-value pairs, and all pairs must match a cluster’s labels in order for that cluster to match.
You can imagine the possible complexity of scheduling decisions (even without domain-specific logistics) around optimizing for ideal spread, cluster capacity and size, etc. We’ll cover some possible expanded features later.
The Reconciler
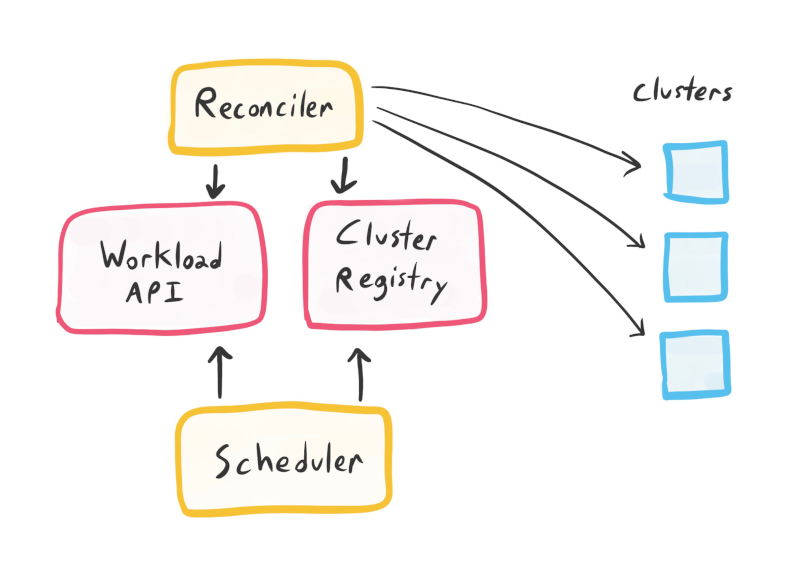
Now we have a reasonable Workload API and ClusterRegistry, which give us a desired state of the system. Something needs to make that state a reality. Hence, we need our final component, the Reconciler. This architecture is starting to bear a lot of resemblance to Kubernetes itself - the Reconciler is analogous to the Kubelets within a cluster.
At a high level, the Reconciler must look at each Cluster in the Workload API, fetch all Workloads mapped to that cluster, and apply them.
This could be implemented as a push-based design, where a global Reconciler (or global set of them) iterates through clusters, fetching the necessary cluster credentials from the Cluster Registry.
It could instead be implemented as a pull-based design, where an agent on each cluster authenticates to a Workload API shim, which authenticates the cluster’s agent and then returns the Workloads for that cluster.
Deeper API Evolutions
These are a collection of thoughts on more complicated but more powerful variants of the APIs described.
Advanced Workloads
Phased Rollout
Deploying a change everywhere at once is a disaster waiting to happen. I’ve seen it happen many times. I also enjoy reading cloud provider postmortems, and “made a change to something globally” is one of the top inciting incidents (the other big one is “a backup system failed in a way that made the original failure worse”).
Regular readers will remember when I created the Kubernetes rollout API alpha as a way to do a gradual deployment for a typical backend/worker pool. The Workload object could support multiple sets of versions in a similar fashion (where each version is all the Kubernetes objects necessary to deploy a given “thing”). By making a Workload support multiple versions, rather than creating multiple Workloads, it is easy for the scheduler to be aware of per-version cluster assignment. For example, version 1 and 2 (at the Workload level) can’t be scheduled on the same cluster, because they will overwrite one another.
Individual versions must be able to specify rollout threshold, and ideally a strategy:
type Workload struct {
versions []WorkloadVersion
selector Selector
clusterReplicas Int
}
type WorkloadVersion struct {
VersionId string
Objects []kubenetesmetav1.Object
Selector Selector
ClusterReplicas Int
}
In this API, there is a global set of replication and selection constraints. Individual versions can set their own constraints, which are prioritized within the Workload’s overall cluster pool (e.g., say you want to roll an update to regions in a specific order). With data filled in, it looks like this:
Workload{
verions: []WorkloadVersion{
{
VersionId: "1",
Objects: ...
},
{
VersionId: "2",
Objects: ...
Selector: map[string]string{
"us-west1"
},
ClusterReplicas: 1,
},
},
Selector: map[string]string{
"env": "production",
"continent": "americas",
},
ClusterReplicas: -1,
}
Phased rollouts raise the possibility of splitting the Workload API, into both current version (i.e. “the last version that was deployed”), and the full intent breakdown. Compare this idea to the Kubernetes Deployment object, and what makes its API so appealing. A deploy system does not need to engage with the deep mechanics of rolling changes, only the new end state. The Deployment controller is responsible for moving the system from the old to new versions. Similarly, separating the Workload API into 2 categories of intent (end state, and an intermediate state) allows for a “dumb” deploy process, and a rich, decoupled rollout control process.
Advanced Selectors
So far, we’ve been assuming a simple label-match model. This works for many cases, and administrators or automation could extend it further by adding hyper-specific labels (e.g. picking and labelling a random cluster to consistently deploy the golden path of an app).
Let’s look at some plausible ways to extend the Selector to add new semantics. Multiple semantics could be supported, by specifying which semantic as part of the Selector.
“Or” Semantics
Instead of requiring an exact match,
change the label’s signature from a map[string]string to a list of pairs (i.e. []KeyValue).
This would allow selectors like “us-east1 or us-west1”.
Taints And Tolerations
Kubernetes pods can select which nodes to run on, based on node labels (called node affinity). Kubernetes also supports a node labelling concept called taints and tolerations, which acts as the inverse. If a node has a taint, pods can’t schedule on it unless they tolerate that taint.
The same idea could be applied to Workload objects and Clusters,
in either direction.
Clusters could reject Workloads that don’t conform to their taints,
such as nodetype=ephemeral
or env=production,
and vice versa for Workloads.
“Not” is another similar semantic.
For example, instead of tainting clusters with nodetype=ephemeral
(forcing workloads to opt in to using that cluster),
disruption-intolerant workloads could specify not nodetype=ephemeral
(asking workloads to explicitly opt out).
This is more explicit than taints, which may or may not be a point in its favour.
An observant reader will note that taints are a helpful feature,
given that a taint implies the absence of a key:value match,
an automated labeler could achieve the same effect by adding a “nomatch” label to
Workloads and clusters, e.g. nomatchnodetype=ephemeral on all clusters and workloads without
nodetype=ephemeral set.
While saying “build your own complex automation” to users is not ideal,
it’s good in a nascent system to bias towards flexibility rather than extreme configuration granularity.
Topological Selection
Spreading workloads across POPs has been a concern in every real or toy system that I’ve ever worked on. This idea is one of my older ones. I’m not entirely convinced of its value, compared to hand-assigning apps to clusters with an app-specific label, but want to share it nonetheless.
In talking about topology, we generally care about suitable spread (geographic, or technical failure domains like data centre AZs). The challenging part is that users have vastly different concerns about spread (user-to-user, and workload-to-workload). For some, presence on all/most major landmasses are acceptable. For others, there must be stronger coverage within each landmass. Redundancy is another question not covered purely by geographic spread - what if you want a small number of regions (e.g. with a cloud provider), but to use multiple AZs in each?
Let’s look at a new Selector schema.
type Selector struct {
labelMatch: map[string]string
clusterReplicasAtLevel: int
subSelector: Selector
}
Selection is done in a tiered, or group-by basis. This allows you to build arbitrary topologies, and represent things like continents, countries, regions, AZs, whatever actually matters for your deployment.
It helps to explain with examples.
This selects any 1 cluster in the US.
Selector {
match: map[string]string{
"country": "us"
},
clusterReplicasAtLevel: 1,
}
This selects 1 cluster in every region.
Selector {
match: map[string]string{
"region": "*"
},
subSelector: Selector {
match: map[string]string{
"az": "*"
},
clusterReplicasAtLevel: 1,
},
clusterReplicasAtLevel: -1, // Let's say negative implies infinite.
}
This selects any 1 region, and any 3 AZs in that region.
Selector {
match: map[string]string{
"region": "*"
},
subSelector: Selector {
match: map[string]string{
"az": "*"
},
clusterReplicasAtLevel: 3,
},
clusterReplicasAtLevel: 1,
}
This approach has obvious downsides, like missing distance-awareness (i.e. if you’re picking 2 regions on a continent, they should probably be on opposite sides). It also implies a high amount of dynamism that is likely undesirable. Entering/leaving a cluster with your workload (or even moreso, a region/datacentre) is generally complex when it comes to networking, data storage, etc. Many organizations would rather pin content to specific locations and be done with it.
Parting Thoughts
Much of this is theoretical, but patterns here have precedence in existing systems, and more experimental systems in development are starting to do things like this.
Building a generic and extendable solution is much harder than building a domain-specific one, and as a result many organizations are reinventing the wheel here. There are many ways to orient the Workload API and Selectors directly around the existing infrastructure, and outright consolidate components like the APIs and Scheduler. If you’re building something generalizable or specific, I would love to hear from you and learn more about your design and constraints.
The backend of this system could plausibly be built in Kubernetes CRDs, but that’s not automatically the best way. There are still limitations with CRDs, and a custom backend could introduce stronger guarantees than the Kubernetes API (for example, supporting transactions if an operation requires modifying multiple objects). Lastly, note that “In Kubernetes And Beyond” was part of the title. A few bits of this, like the specifics of the ClusterRegistry API, assume Kubernetes. However, this whole approach could work with any system that can codify and apply workloads in distinct clusters/subsystems.