There’s a pattern I’ve seen several times while reviewing incidents. Someone says “the service <crashed | served blank data> because the cache was unavailable”. To which I always ask: is that a cache?
Caches store a copy of data for faster access. There are many reasons to do so, such as reducing I/O time, reducing data transfer costs, or reducing the critical path of a call. That last point is where caches can go ary.
The general cache pattern is simple. Check if a value is in the cache, if it is then return it, if it isn’t, do the more expensive fetch, then return that data and save it to the cache. This is why we talk about cache hit time (the time to fetch data that is in the cache), and cache miss time (the time to fetch data that was not in the cache).
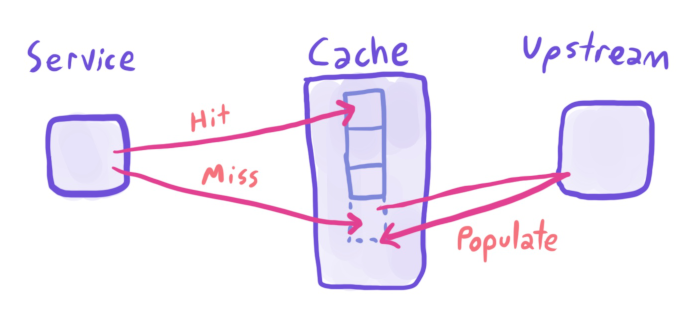
There is another cache pattern, often used when the miss rate is expensive or the dataset is small/static. You can periodically take a snapshot of the world (EG product id->name mappings), and save that data to a cache, out-of-band of cache requests. There are good reasons to do this, such as “we want to reduce the dependency on the product-catalogue service”, or “we see poor performance when querying uncommon items”.
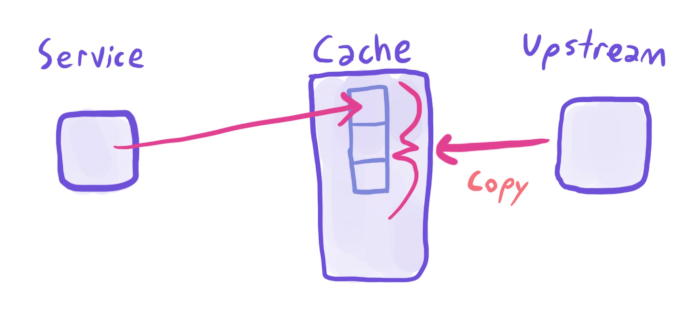
However, populating the cache like this has a crucial downside. Suppose you’re using this cache for coupon codes. I want to buy a product, and I have a coupon code, CACHEMISS20. CACHEMISS20 is a new code, that hasn’t yet been picked up by all the coupon caches. I go to check out, and - uh oh - I can’t use the coupon, and abandon my cart.
What went wrong here? By not fetching data on a cache miss, you are at the mercy of refresh rates.
Going back to those aforementioned incidents, problems will inevitably occur with out-of-band cache updates. Maybe a script stopped running, or access to an upstream system was lost, or keys were renamed… The end result is that the whole cache goes bad.
If programmers consuming the cache get into the mindset that the cache is always available/populated/accurate, they will likely not think about or handle failure cases. This is how you get incidents like “requests crashed because the cache was unavailable/empty”, or “X data stopped updating at Y time”, or “no new Xs after Y time”. Databases are a source of truth, caches are not. If data isn’t in a cache, it doesn’t mean that you return nil/0/“”/etc.
Treat your caches like caches, not like databases.